
Jun 24, 2024
Developers, It's Time to Rethink Your Programming Stack. Go Language Agnostic!
In programming, the concept of a one-size-fits-all language is a fallacy. Different languages offer …


Pixie can be utilized for gathering monitoring metrics from your clusters. It offers you the benefit of having pre-written scripts, as well as custom scripts that extrapolate data. The custom scripts are written in Pixie’s very own language, PXL, which is similar to Python. Last week, we had been working on creating our first custom PXL script to gather data . In this tutorial, lets focus on customizing the data we have gathered and tuning it to our own preferences.
Within the PXL language, we can see that we use dataframes to interact with our data. For those of you familiar with Python, specifically pandas, this blog post will come as second nature to you. Dataframes are just
tabular representations of data. You can think of a dataframe as a spreadsheet, but way more powerful.
You can tell from the script we wrote last week that the columns included were from the process_stats table. (see script below)
# We import px, which is the library we will be using to add extra data to our table.
import px
# We gather data from the last 5 minutes, from the `process_stats` table, and create a dataframe from it.
df = px.DataFrame(table='process_stats', start_time='-5m')
# Below, we are adding extra data to our table, using `context` or `execution_time_functions`
df.pod_id = df.ctx['pod_id']
df.pod_name = px.upid_to_pod_name(df['upid'])
df.pod_id = px.pod_name_to_pod_id(df['pod_name'])
df.cmd = df.ctx['cmdline']
df.pid = df.ctx['pid']
df.container_name = df.ctx['container_name']
df.container_id = df.ctx['container_id']
# We group the dataframe based on certain attributes, and aggregate the data.
df = df.groupby(['pid', 'cmd', 'upid', 'container_name']).agg()
# We display the dataframe.
px.display(df, 'processes_table')
This script used basic functions on the dataframe, such as adding new columns. It also used slightly more advanced functions such as the groupby function, and the aggregation function .agg().
Let’s get right into how we can enhance our PXL scripts by manipulating data.
On top of just adding a few extra columns, we can also join two tables together based on common columns shared by the two tables. This process is called merging. Take a look at the code below for an example/explanation.
# We import px, which is the library we will be using to add extra data to our table.
import px
# We gather data from the last 5 minutes, from the `conn_stats` table,
# and create a dataframe from it.
df = px.DataFrame('conn_stats', start_time='-5m')
# We also gather data from the `http_events` table.
http_e_df = px.DataFrame('http_events', start_time='-5m')
# We can now combine the two tables, using the merge function.
df = df.merge(http_e_df, how='left', left_on=['time_', 'upid'], right_on=['time_', 'upid'], suffixes=['', '_x'])
px.display(df, 'conn_stats_and_http_events_table')
In the script above, we are using the merge function to join columns from the http_events table to the conn_stats table. Here is a brief explanation of what the parameters in this function mean:
how: how we are going to be joining one table to another.'left' means we will keep all data from the left table.'right' means we keep all data from the right table.'inner' means we will only be keeping the data that is present in both tables.
'outer' means that we will be keep all data present in both tables.left_on/right_on: These define the columns which we will compare between the two tables to align the data correctly. In the code above, we are aligning data based on the time_ and upid columns.suffixes: defines what strings to attach to the duplicate columns in the resulting table.
At the end of the merging done in this script, you will notice that we have columns from both tables. Yet, we will only have observations (rows) from the conn_stats table, since it is the left table.We can drop certain columns that we would not like from a table. For example, if there is a column that is duplicated from the previous merge we have done, we can drop it after merging. Take a look below:
...
# We can now combine the two tables, using the merge function.
df = df.merge(http_e_df, how='left', left_on=['time_', 'upid'], right_on=['time_', 'upid'], suffixes=['', '_x'])
# we get rid of duplicate values such as `time__x` and `upid_x`
df = df.drop(['time__x', 'upid_x'])
...
Notice that the colums we are dropping have the duplicate suffixes attached to their names. This ensures that the original columns are still present, so that we do not lose the data.
We can add custom columns to our data based on calculations we have done ourselves, or calculations based on other columns. This process is called mapping. For example, we might want to convert bytes to megabytes. This can be done via:
df['req_body_size'] = df['req_body_size']/1.0e6
We can also add custom columns with whatever data we would like. If I wanted a column named foo, with the attribute bar added to each observation, I could do that using the following:
df['foo'] = "bar"
We can filter data within our script using PXL’s filter function. This functionality is similar to what is done in Python’s pandas package. In the example below, I am filtering to include the rows that
have their bytes_sent value higher than 65399738:
df = df[df['bytes_sent'] > 65399738]
Pixie docs list a whole bunch of useful functions that can be applied to PXL dataframes . Some of my favorites are:
Dataframe.head(): For when you need only a certain number of rows to be received from Pixie. This is extremely helpful in debugging while you are writing PXL scripts.Dataframe.groupby(): As we have used in our previous PXL blog
.Dataframe.stream(): For when you have so much data that you need it on a streaming basis.In this blog, we have understood what PXL dataframes are, and the special dataframe functions we can use to enhance our PXL script and manipulate our data. Feel free to look at the PXL Docs to learn more.

Hannan Khan holds a Masters in Computer Science from UT Arlington, with a specialization in Intelligent Systems. His passions include …
In programming, the concept of a one-size-fits-all language is a fallacy. Different languages offer …
Hackers pose a persistent threat to businesses, devising new ways to steal data and disrupt operations. They …
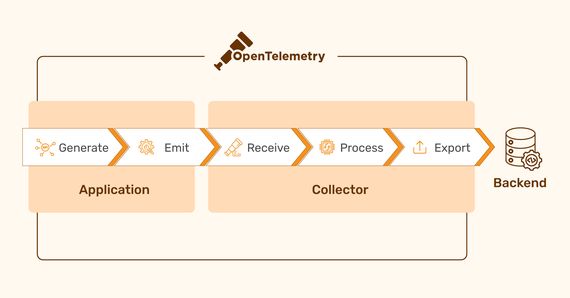
Modern software development often leverages distributed architectures to achieve faster development cycles …
Finding the right talent is pain. More so, keeping up with concepts, culture, technology and tools. We all have been there. Our AI-based automated solutions helps eliminate these issues, making your teams lives easy.
Contact Us